

MonolithFoundation/Bumblebee
Text Generation
•
Updated
•
3
•
1
The dataset viewer should be available soon. Please retry later.
15 trillion tokens of the finest data the 🌐 web has to offer
The 🍷 FineWeb dataset consists of more than 15T tokens of cleaned and deduplicated english web data from CommonCrawl. The data processing pipeline is optimized for LLM performance and ran on the 🏭 datatrove library, our large scale data processing library.
🍷 FineWeb was originally meant to be a fully open replication of 🦅 RefinedWeb, with a release of the full dataset under the ODC-By 1.0 license. However, by carefully adding additional filtering steps, we managed to push the performance of 🍷 FineWeb well above that of the original 🦅 RefinedWeb, and models trained on our dataset also outperform models trained on other commonly used high quality web datasets (like C4, Dolma-v1.6, The Pile, SlimPajama, RedPajam2) on our aggregate group of benchmark tasks.
That said, we think there is still room for additional filtering and improvement and intend to continue exploring how to improve the dataset quality in coming versions of 🍷 FineWeb.
Along with the dataset, which includes all CommonCrawl dumps since 2013, we also share all the code needed to fully reproduce our processing setup using the 🏭 datatrove library here. To enable full replication of our results, we have also published the small ablation models we have trained using nanotron to validate the dataset and compare it with other reference datasets. You will find them here, with checkpoints every 1000 steps. We have also published our evaluation results here. Our evaluation setup is available here.
You will find details on the different processing decisions we took and some interesting explorations of deduplication methods and differences between CommonCrawl dumps in our technical report to be published in the coming days.
You can load the full dataset or a specific crawl/dump (see table below). Dumps have the format CC-MAIN-(year)-(week number).
datatrove
from datatrove.pipeline.readers import ParquetReader
# limit determines how many documents will be streamed (remove for all)
# to fetch a specific dump: hf://datasets/HuggingFaceFW/fineweb/data/CC-MAIN-2024-10
data_reader = ParquetReader("hf://datasets/HuggingFaceFW/fineweb/data", limit=1000)
for document in data_reader():
# do something with document
print(document)
###############################
# OR for a processing pipeline:
###############################
from datatrove.executor import LocalPipelineExecutor
from datatrove.pipeline.readers import ParquetReader
from datatrove.pipeline.filters import LambdaFilter
from datatrove.pipeline.writers import JsonlWriter
pipeline_exec = LocalPipelineExecutor(
pipeline=[
ParquetReader("hf://datasets/HuggingFaceFW/fineweb/data/CC-MAIN-2024-10", limit=1000),
LambdaFilter(lambda doc: "hugging" in doc.text),
JsonlWriter("some-output-path")
],
tasks=10
)
pipeline_exec.run()
huggingface_hub
from huggingface_hub import snapshot_download
folder = snapshot_download(
"HuggingFaceFW/fineweb",
repo_type="dataset",
local_dir="./fineweb/",
allow_patterns="data/CC-MAIN-2023-50/*")
For faster downloads, make sure to install pip install huggingface_hub[hf_transfer] and set the environment variable HF_HUB_ENABLE_HF_TRANSFER=1.
datasets
from datasets import load_dataset
fw = load_dataset("HuggingFaceFW/fineweb", name="CC-MAIN-2024-10", split="train", streaming=True)
| Dump | Time period | Disk size (GB) | gpt2 tokens (billions) |
|---|---|---|---|
| CC-MAIN-2024-10 | February/March 2024 | 432.0 | 157.2 |
| CC-MAIN-2023-50 | November/December 2023 | 650.0 | 239.7 |
| CC-MAIN-2023-40 | September/October 2023 | 578.6 | 213.0 |
| CC-MAIN-2023-23 | May/June 2023 | 585.5 | 218.5 |
| CC-MAIN-2023-14 | March/April 2023 | 543.3 | 202.4 |
| CC-MAIN-2023-06 | January/February 2023 | 540.3 | 198.6 |
| CC-MAIN-2022-49 | November/December 2022 | 557.9 | 205.6 |
| CC-MAIN-2022-40 | September/October 2022 | 535.0 | 198.2 |
| CC-MAIN-2022-33 | August 2022 | 381.4 | 141.1 |
| CC-MAIN-2022-27 | June/July 2022 | 506.4 | 187.1 |
| CC-MAIN-2022-21 | May 2022 | 573.7 | 211.7 |
| CC-MAIN-2022-05 | January 2022 | 464.7 | 171.3 |
| CC-MAIN-2021-49 | November/December 2021 | 368.2 | 135.8 |
| CC-MAIN-2021-43 | October 2021 | 601.5 | 221.0 |
| CC-MAIN-2021-39 | September 2021 | 518.9 | 190.6 |
| CC-MAIN-2021-31 | July/August 2021 | 593.9 | 217.7 |
| CC-MAIN-2021-25 | June 2021 | 424.4 | 155.7 |
| CC-MAIN-2021-21 | May 2021 | 455.9 | 167.4 |
| CC-MAIN-2021-17 | April 2021 | 556.0 | 204.1 |
| CC-MAIN-2021-10 | February/March 2021 | 463.2 | 169.6 |
| CC-MAIN-2021-04 | January 2021 | 562.4 | 205.4 |
| CC-MAIN-2020-50 | November/December 2020 | 422.8 | 154.3 |
| CC-MAIN-2020-45 | October 2020 | 426.9 | 155.8 |
| CC-MAIN-2020-40 | September 2020 | 555.5 | 202.4 |
| CC-MAIN-2020-34 | August 2020 | 379.6 | 138.7 |
| CC-MAIN-2020-29 | July 2020 | 489.6 | 178.7 |
| CC-MAIN-2020-24 | May/June 2020 | 398.7 | 145.1 |
| CC-MAIN-2020-16 | March/April 2020 | 454.0 | 165.6 |
| CC-MAIN-2020-10 | February 2020 | 369.6 | 134.7 |
| CC-MAIN-2020-05 | January 2020 | 483.3 | 176.4 |
| CC-MAIN-2019-51 | December 2019 | 359.3 | 130.9 |
| CC-MAIN-2019-47 | November 2019 | 395.4 | 144.0 |
| CC-MAIN-2019-43 | October 2019 | 422.3 | 153.9 |
| CC-MAIN-2019-39 | September 2019 | 394.4 | 143.7 |
| CC-MAIN-2019-35 | August 2019 | 454.2 | 165.4 |
| CC-MAIN-2019-30 | July 2019 | 416.6 | 151.5 |
| CC-MAIN-2019-26 | June 2019 | 412.9 | 150.1 |
| CC-MAIN-2019-22 | May 2019 | 432.8 | 157.4 |
| CC-MAIN-2019-18 | April 2019 | 426.7 | 155.3 |
| CC-MAIN-2019-13 | March 2019 | 417.8 | 152.1 |
| CC-MAIN-2019-09 | February 2019 | 467.2 | 169.9 |
| CC-MAIN-2019-04 | January 2019 | 438.1 | 158.7 |
| CC-MAIN-2018-51 | December 2018 | 498.6 | 180.8 |
| CC-MAIN-2018-47 | November 2018 | 437.7 | 158.9 |
| CC-MAIN-2018-43 | October 2018 | 468.8 | 169.9 |
| CC-MAIN-2018-39 | September 2018 | 429.2 | 155.2 |
| CC-MAIN-2018-34 | August 2018 | 408.2 | 148.0 |
| CC-MAIN-2018-30 | July 2018 | 501.5 | 181.4 |
| CC-MAIN-2018-26 | June 2018 | 467.5 | 170.0 |
| CC-MAIN-2018-22 | May 2018 | 398.6 | 144.2 |
| CC-MAIN-2018-17 | April 2018 | 435.1 | 158.1 |
| CC-MAIN-2018-13 | March 2018 | 471.5 | 171.5 |
| CC-MAIN-2018-09 | February 2018 | 490.2 | 178.0 |
| CC-MAIN-2018-05 | January 2018 | 493.5 | 180.7 |
| CC-MAIN-2017-51 | December 2017 | 442.6 | 161.5 |
| CC-MAIN-2017-47 | November 2017 | 457.9 | 167.1 |
| CC-MAIN-2017-43 | October 2017 | 535.6 | 194.9 |
| CC-MAIN-2017-39 | September 2017 | 444.5 | 162.3 |
| CC-MAIN-2017-34 | August 2017 | 503.2 | 183.4 |
| CC-MAIN-2017-30 | July 2017 | 439.2 | 161.2 |
| CC-MAIN-2017-26 | June 2017 | 491.5 | 179.8 |
| CC-MAIN-2017-22 | May 2017 | 441.0 | 161.5 |
| CC-MAIN-2017-17 | April 2017 | 596.8 | 218.6 |
| CC-MAIN-2017-13 | March 2017 | 579.8 | 212.1 |
| CC-MAIN-2017-09 | February 2017 | 492.2 | 180.2 |
| CC-MAIN-2017-04 | January 2017 | 474.3 | 174.4 |
| CC-MAIN-2016-50 | December 2016 | 448.9 | 165.4 |
| CC-MAIN-2016-44 | October 2016 | 467.8 | 172.0 |
| CC-MAIN-2016-40 | September 2016 | 386.1 | 142.8 |
| CC-MAIN-2016-36 | August 2016 | 339.6 | 126.3 |
| CC-MAIN-2016-30 | July 2016 | 346.0 | 128.4 |
| CC-MAIN-2016-26 | June 2016 | 256.5 | 95.5 |
| CC-MAIN-2016-22 | May 2016 | 310.9 | 115.4 |
| CC-MAIN-2016-18 | April 2016 | 298.1 | 110.8 |
| CC-MAIN-2016-07 | February 2016 | 342.7 | 127.2 |
| CC-MAIN-2015-48 | November 2015 | 353.9 | 131.3 |
| CC-MAIN-2015-40 | September 2015 | 284.0 | 105.5 |
| CC-MAIN-2015-35 | August 2015 | 359.4 | 133.2 |
| CC-MAIN-2015-32 | July 2015 | 352.4 | 130.1 |
| CC-MAIN-2015-27 | June 2015 | 335.5 | 124.0 |
| CC-MAIN-2015-22 | May 2015 | 380.2 | 140.4 |
| CC-MAIN-2015-18 | April 2015 | 389.0 | 143.8 |
| CC-MAIN-2015-14 | March 2015 | 337.5 | 124.5 |
| CC-MAIN-2015-11 | February 2015 | 361.4 | 133.3 |
| CC-MAIN-2015-06 | January 2015 | 356.1 | 131.3 |
| CC-MAIN-2014-52 | December 2014 | 388.5 | 143.3 |
| CC-MAIN-2014-49 | November 2014 | 319.9 | 117.7 |
| CC-MAIN-2014-42 | October 2014 | 371.1 | 136.4 |
| CC-MAIN-2014-41 | September 2014 | 408.1 | 150.2 |
| CC-MAIN-2014-35 | August 2014 | 395.7 | 145.6 |
| CC-MAIN-2014-23 | July 2014 | 425.0 | 156.5 |
| CC-MAIN-2014-15 | April 2014 | 369.1 | 135.7 |
| CC-MAIN-2014-10 | March 2014 | 396.2 | 146.2 |
| CC-MAIN-2013-48 | Winter 2013 | 396.8 | 145.9 |
| CC-MAIN-2013-20 | Summer 2013 | 393.9 | 144.5 |
| Total | 41880.2 | 15352.9 |
We conducted our dataset performance ablations and evaluations by training a series of 1.8B parameters models on 27 billion tokens. To compare 🍷 FineWeb with other datasets, we also trained one of these 1.8B models per target dataset, on 350 billion tokens sampled from it (or the entire dataset when its size was < 350 billion tokens).
The detailed configurations for training the 1.8B parameters ablation model can be found here (link will be added soon).
To conduct the ablations for each of our dataset filtering choices, we selected a set of benchmarks which we identified as “high-signal” benchmarks. These benchmarks were selected according to the following criteria:
We used the following list of benchmark for our ablation runs:
To compare runs we consider an aggregate score, the average of the scores for these tasks.
The prompts for all these benchmarks are formatted in order to compute and compare the log-likelihood of the full answers for each multiple choice question. All the implementation details for the benchmarks are available in lighteval here.
We compared 🍷 FineWeb with the following datasets:
You will find these models on this collection. We have uploaded checkpoints at every 1000 training steps. You will also find our full evaluation results here.
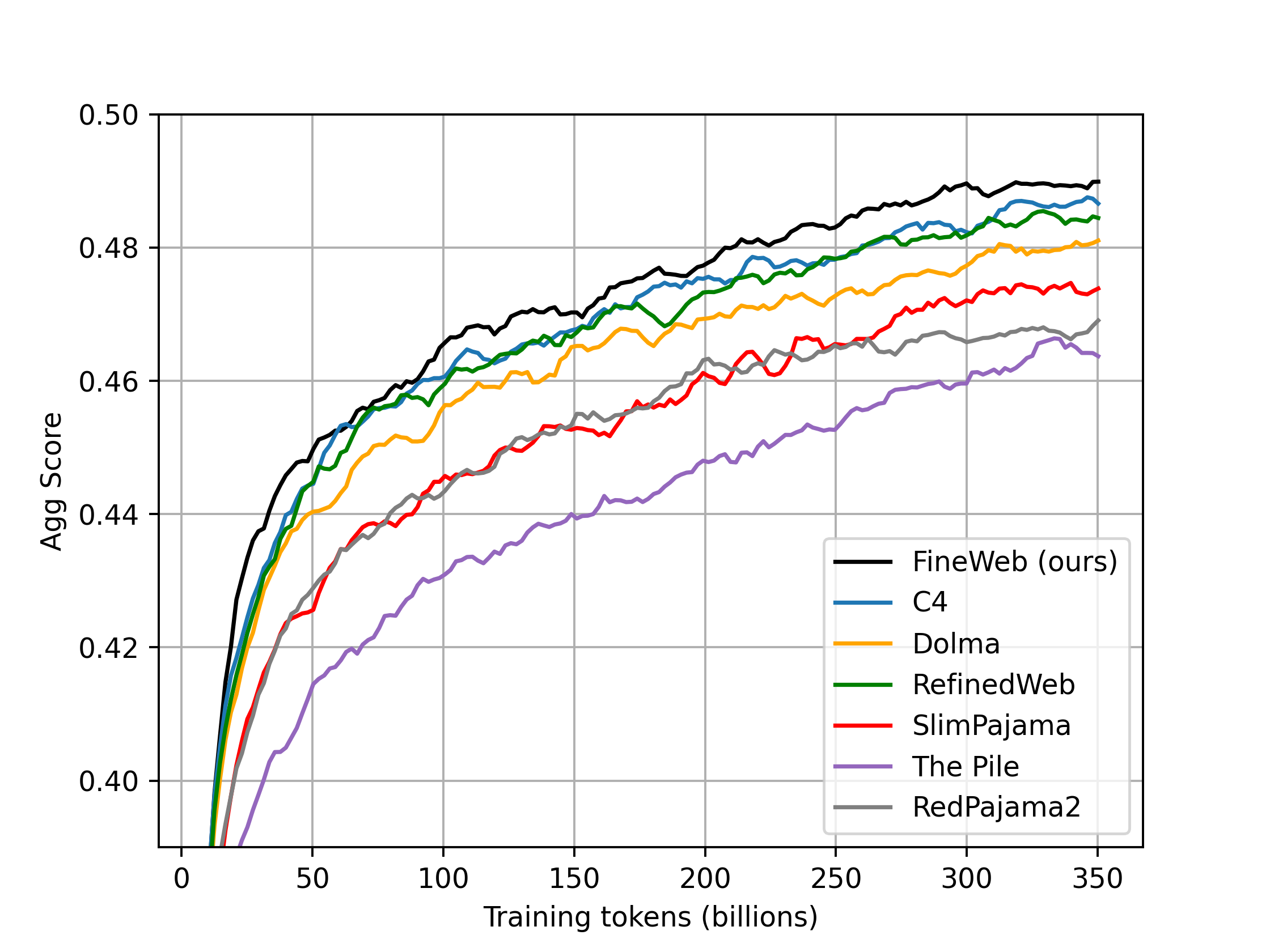
Note: The plot is smoothed by averaging 5k steps in a rolling window.
This dataset was created by processing 95 CommonCrawl dumps comprising web data crawled from the summer of 2013 to March of 2024. 🍷 FineWeb includes a variety of domains and topics in English and is primarily intended to be used as a research artifact on public data in the context of pretraining dataset for large language models. The CommonCrawl data was carefully processed, filtered and deduplicated with the 🏭 datatrove library, resulting in the largest publicly available clean LLM pretraining dataset, counting around 15 trillion tokens (gpt2 tokenizer).
The following is an example sample from the dataset. It is part of the CC-MAIN-2021-43 and was crawled on 2021-10-15T21:20:12Z.
{
"text": "This is basically a peanut flavoured cream thickened with egg yolks and then set into a ramekin on top of some jam. Tony, one of the Wedgwood chefs, suggested sprinkling on some toasted crushed peanuts at the end to create extra crunch, which I thought was a great idea. The result is excellent.",
"id": "<urn:uuid:e5a3e79a-13d4-4147-a26e-167536fcac5d>",
"dump": "CC-MAIN-2021-43",
"url": "<http://allrecipes.co.uk/recipe/24758/peanut-butter-and-jam-creme-brulee.aspx?o_is=SimilarRecipes&o_ln=SimRecipes_Photo_7>",
"date": "2021-10-15T21:20:12Z",
"file_path": "s3://commoncrawl/crawl-data/CC-MAIN-2021-43/segments/1634323583083.92/warc/CC-MAIN-20211015192439-20211015222439-00600.warc.gz",
"language": "en",
"language_score": 0.948729,
"token_count": 69
}
text (string): the main text contentid (string): original unique identifier for this sample from CommonCrawldump (string): the CommonCrawl dump this sample was a part ofurl (string): url to the original page where text was presentdate (string): crawl date (from CommonCrawl)file_path (string): s3 path for the individual CommonCrawl warc file containing this samplelanguage (string): en for all the samples in this datasetlanguage_score (float): language prediction score (0.01.0) as reported by the fastText language classifiertoken_count (int): number of tokens when applying the gpt2 tokenizer to this sampleThe default subset includes the entire dataset. If you would like to only use the data from a particular CommonCrawl dump, you can use the dump name as a subset. You will find the full list of available dumps on the table above.
From experiments we have run, not all dumps give the same performance. For relatively small trainings (<400 billion tokens) we recommend using the recent CC-MAIN-2023-50 and CC-MAIN-2024-10. We will share more details about these experiments on our future technical report.
While multiple open-weights models have regularly been released in recent months, these releases often do not include the model's training data. With 🍷 FineWeb we aim to provide the open source community with a very large clean pretraining dataset that can be used to push the envelope on truly open source models (open source models where data is also released).
The source data consists of webpages crawled by the CommonCrawl foundation over the 2013-2024 time period.
We then extracted the main page text from the html of each webpage, carefully filtered each sample and deduplicated each individual CommonCrawl dump/crawl.
While we originally intended to deduplicate the dataset as a whole, our ablations showed that training on a sampling of individually deduplicated dumps/crawls outperformed training on a sampling of all the dumps/crawls deduplicated together. We will discuss this further in our technical report.
We used the 🏭 datatrove library to process the data.
You can find a working script that launches the entire processing pipeline here.
The data processing pipeline consists of:
en language score lower than 0.65terminal_punct ruleWe augment the original samples with the language, language_score and token_count annotations. The language related annotations are automatically generated by our language filter. token_count is generated by applying the gpt2 tokenizer to the text column.
We anonymize email addresses and public IP addresses.
For emails, we apply a regex pattern and replace any occurrence of an email address with either email@example.com or firstname.lastname@example.org. For IP addresses, we also employ a regex pattern and then further filter to only anonymize IP addresses allocated for public networks. Matched IP addresses are then replaced with one of the following randomly generated IP addresses, which at the time of dataset creation were not responding to ping requests: 22.214.171.124, 126.96.36.199, 188.8.131.52, 184.108.40.206, 220.127.116.11, and 18.104.22.168. We decided against applying regex patterns for phone numbers due to the high false positive rate.
Despite our efforts, given that 🍷 FineWeb is sourced from the internet at large, it is very likely that some personable identifiable information (PII) will be present. If you find your own PII in 🍷 FineWeb and would like it removed, please fill out our PII removal form.
With the release of this dataset we aim to make model training more accessible to the machine learning community at large.
While multiple open-weights models with strong performance have been publicly released in the past, more often than not these releases are not accompanied by the corresponding training dataset. This is unfortunate as the dataset specificities and characteristics have been demonstrated to have a very large impact and role in the performances of the models. As the creation of a high quality training dataset is a fundamental requirement to training an LLM capable of excelling at downstream tasks, with 🍷 FineWeb we (a) not only make the dataset creation process more transparent, by sharing our entire processing setup including the codebase used, we also (b) help alleviate the costs of dataset curation, both in time and in compute, for model creators by publicly releasing our dataset with the community.
Efforts were made to minimize the amount of NSFW and toxic content present in the dataset by employing filtering on the URL level. However, there are still a significant number of documents present in the final dataset that could be considered toxic or contain harmful content. As 🍷 FineWeb was sourced from the web as a whole, any harmful biases typically present in it may be reproduced on our dataset.
We deliberately avoided using machine learning filtering methods that define text quality based on the similarity to a “gold” source such as wikipedia or toxicity classifiers as these methods have been known to disproportionately remove content in specific dialects and overclassify as toxic text related to specific social identities, respectively.
As a consequence of some of the filtering steps applied, it is likely that code content is not prevalent in our dataset. If you are training a model that should also perform code tasks, we recommend you use 🍷 FineWeb with a code dataset, such as The Stack v2. You should also probably consider complementing 🍷 FineWeb with specialized curated sources (such as Wikipedia, for example) as they will likely have better formatting than the wikipedia content included in 🍷 FineWeb (we did not tailor the processing to individual websites).
The dataset is released under the Open Data Commons Attribution License (ODC-By) v1.0 license. The use of this dataset is also subject to CommonCrawl's Terms of Use.
We plan to not only continue but also expand our efforts to create open-source high quality training datasets and to improve 🍷 FineWeb itself in future iterations.
@software{penedo2024fineweb,
author = {Penedo, Guilherme and Kydlíček, Hynek and von Werra, Leandro and Wolf, Thomas},
title = {FineWeb},
month = April,
year = 2024,
doi = { 10.57967/hf/2092 },
url = {https://huggingface.co/datasets/HuggingFaceFW/fineweb}
}




