
ALIGN (base model)
The ALIGN model was proposed in "Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision" by Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc V. Le, Yunhsuan Sung, Zhen Li, Tom Duerig. ALIGN features a dual-encoder architecture with EfficientNet as its vision encoder and BERT as its text encoder, and learns to align visual and text representations with contrastive learning. Unlike previous work, ALIGN leverages a massive noisy dataset and shows that the scale of the corpus can be used to achieve SOTA representations with a simple recipe.
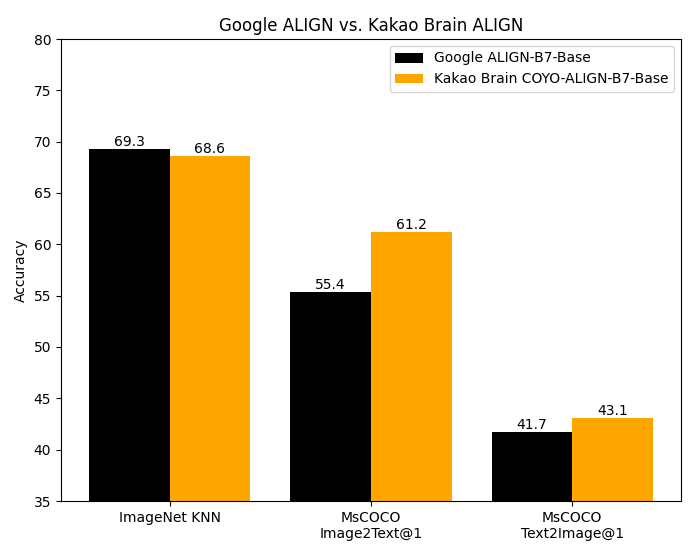
The code for ALIGN was not publicly released, the base model is converted from the original implementation of the Kakao Brain team. This implementation follows the same architecture and hyperparameters as provided in the original Google model but is trained on the open source COYO dataset. Google’s ALIGN model, while trained on a huge dataset of 1.8 billion image-text pairs, cannot be replicated as the datasets is not public. Kakao Brain's ALIGN is on-par or outperforms Google ALIGN's reported metrics despite being trained on the much smaller, albeit carefully curated COYO-700M dataset.
COYO-700M Dataset
COYO is an image-text dataset of 700 million pairs similar to Google's ALIGN 1.8B image-text dataset which is a collection of "noisy" alt-text and image pairs from webpages, but open-source. COYO-700M and ALIGN 1.8B are "noisy" because minimal filtering was applied. COYO is similar to the other open-source image-text dataset, LAION but with the following differences. While LAION 2B is a much larger dataset of 2 billion English pairs, compared to COYO’s 700 million pairs, COYO pairs come with more metadata that give users more flexibility and finer-grained control over usage. The following table shows the differences: COYO comes equipped with aesthetic scores for all pairs, more robust watermark scores, and face count data.
| COYO | LAION 2B | ALIGN 1.8B |
|---|---|---|
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | Google Cloud API |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English | 1.8 billion |
| From CC 2020 Oct - 2021 Aug | From CC 2014-2020 | NA |
| Aesthetic Score | Aesthetic Score Partial | NA |
| More robust Watermark score | Watermark Score | NA |
| Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
COYO is available on the hub as a dataset.
Use with Transformers
Zero-Shot Image Classification
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
candidate_labels = ["an image of a cat", "an image of a dog"]
inputs = processor(text=candidate_labels, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
Multi-Modal Embedding Retrieval
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "an image of a cat"
inputs = processor(text=text, images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# multi-modal text embedding
text_embeds = outputs.text_embeds
# multi-modal image embedding
image_embeds = outputs.image_embeds
Alternatively, retrieve image or text embeddings separately.
import requests
import torch
from PIL import Image
from transformers import AlignProcessor, AlignModel
processor = AlignProcessor.from_pretrained("kakaobrain/align-base")
model = AlignModel.from_pretrained("kakaobrain/align-base")
# image embeddings
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
# text embeddings
text = "an image of a cat"
inputs = processor(text=text, return_tensors="pt")
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
Model Use
Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the ALIGN paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
- Downloads last month
- 11,424